Usogres replication test report
Dobrica Pavlinusic (dpavlin(at)rot13.org) 2002-04-22
While searching for solution to provide highly available web service to our portal site, I came across Usogres which claimed to be on-line backup utility. Why did the author decide to call it like that is still unknown to me, but it came to my mind that it could be useful as a tool to provide coherent data between two PostgreSQL databases. However, since this project comes with no performance measurement, I had to make my own.
Test data
Test database consists of two tables, one contains all calls made by cell phone during last two years, and another with numbers and names of people from my Palm Pilot.
I usually use that database because it's quite large (482 rows in address book and 5575 rows in calls table), and I already have two useful SQL SELECT WHERE queries for it. Those queries return number of calls and address book data for records in calls table which can be matched (quite simple SQL query stored in shell script report.sh) and same data but with outer join match (implemented using union because it was done back in PostgreSQL 6.5 days) called report2.sh.
For testing I also used process of creating tables and indices (really fast one, as you will see in moment) and filling of data (from textual files and html files which exercise disk and RDBMS at same time).
Test hardware and software
Master copy of database is stored on reus which is my laptop, with Mobile Pentium MMX on 233 MHz (466.94 bogomips) with 112 Mb of RAM (and enough swap space, but whole database can be cached in RAM), kernel 2.2.19 and PostgreSQL 7.1.2 (running Debian Woody, of course :-).
Other machine which served as a copy of database is called wihpy and it's another laptop, this time with Pentium III (Coppermine) on 700 MHz (much faster machine with 1363.14 bogomips, we'll see this difference in test data as well) with 256 Mb of RAM running Linux under VMWare with just 96 Mb allocated to Linux. It also runs kernel 2.2.19 and PostgreSQL 7.2.1 (it's not mistake, I used mix of PostgreSQL 7.1.2 and 7.2.1).
I used Usogres version 0.8.0.
Reference results
All test where performed three times and then averaged to get the value for further calculations. First, I ran make fill (which created database structure), make racuni (which filled data from text files and html files to database), report.sh (simple SQL SELECT WHERE report) and report2.sh (SQL SELECT report which emulates outer join using union) on reus and wihpy without Usogres just to get reference numbers.
As you can see from following table, results are quite interesting.
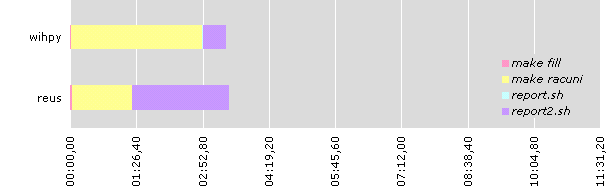
| reus | wihpy | |
|---|---|---|
| make fill | 00:02,48 | 00:01,36 |
| make racuni | 01:17,77 | 02:51,28 |
| report.sh | 00:00,80 | 00:00,33 |
| report2.sh | 02:06,01 | 00:30,01 |
| total: | 03:27,05 | 03:22,98 |
wihpy is four times faster executing report report2.sh (processor power helps), while more than twice slower while filling data into database. I think that this is due to VMWare disk emulation (I used dedicated partition, and not disk file, but it seems that it didn't help).
Usogres comes into play
Next, I installed two instances of postmaster and Usogres on reus to test Usogres compilation and get some numbers. Results where disappointing. It took more than four times longer to complete tests than without Usogres (and with only one PostgreSQL).
To be honest, this huge increase in time can mostly be attributed to high disk load which is result of insert queries in database. Non-disk intensive operations (like report2.sh) took just twice as long (which is expected because two postmasters have to process that query on same machine).
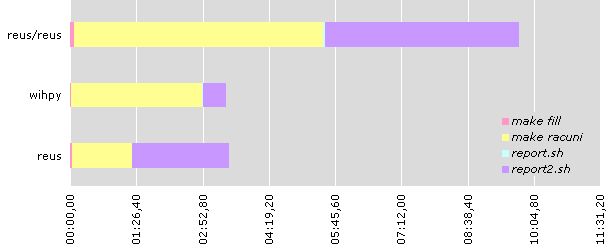
| reus | wihpy | reus/reus | |
|---|---|---|---|
| make fill | 00:02,48 | 00:01,36 | 00:05,07 |
| make racuni | 01:17,77 | 02:51,28 | 05:24,88 |
| report.sh | 00:00,80 | 00:00,33 | 00:02,08 |
| report2.sh | 02:06,01 | 00:30,01 | 04:14,10 |
| total: | 03:27,05 | 03:22,98 | 09:46,13 |
Real setup
The last step of this test was replication from original database on reus to copy on wihpy. That resulted in longer wait than the reference testing of reus and wihpy, but still quicker than two copies on reus.
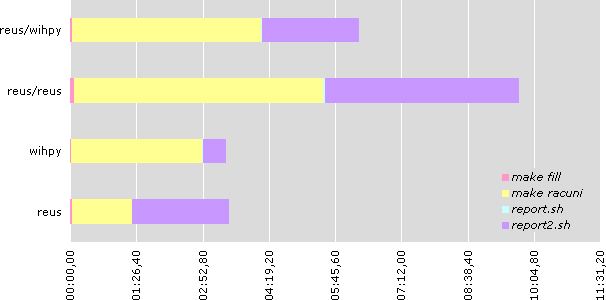
| reus | wihpy | reus/reus | reus/wihpy | |
|---|---|---|---|---|
| make fill | 00:02,48 | 00:01,36 | 00:05,07 | 00:03,09 |
| make racuni | 01:17,77 | 02:51,28 | 05:24,88 | 04:05,61 |
| report.sh | 00:00,80 | 00:00,33 | 00:02,08 | 00:01,37 |
| report2.sh | 02:06,01 | 00:30,01 | 04:14,10 | 02:06,60 |
| total: | 03:27,05 | 03:22,98 | 09:46,13 | 06:16,66 |
It's important to note that each query sent to Usogres will take at least as much time as needed for slowest RDBMS to finish. Time to fill database (make racuni) took twice as long. That could be because (a) insert queries are serialized [and examination of Usogres code showed no proof for that] or (b) network traffic is considerable.
On the other side, complex report report2.sh took about same time as on reus alone (which is slower). This proves that queries are indeed sent to both nodes at once, but blocking until both nodes are finished.
Conclusion
So, all in one we might conclude that select queries don't degrade much performance-wise, while inserts do. This might not be correct conclusion because I installed copy of database server on VMWare emulated machine which has terribly slow disk. However, insert queries will suffer greater performance degradation than select. I would estimate that slowdown of 30% is reasonable when Usogres in introduced in environment (with typical mix of select and insert queries).
Thanks and links
Much thanks goes to Tetsuichi HOSOKAWA (hosokawa(at)dear-jpn.com) who wrote Usogres. Also, we must credit PostgreSQL team for such a great database.
Raw file with results is available as usogres.log.